The term 'Artificial Intelligence' has taken on several definitions since its first conception. Ada
Lovelace, by many counts the first "computer programmer", had already speculated a machine's
abilities to become "intelligent" before computers were even computers. Early academics and
philosophers like Church, Turing, Gödel, Russell, and other pantheons of computing theory have
explored the possibilities, limits, and processes needed to give an unliving, inanimate,
electromechanical device the power to make decisions. Even a recent (although now +40-year-old)
exploration into the concept with Douglas Hofstadter's iconic work,
Gödel, Escher, Bach explored more than just 'decision-making', but rather the
possibility of 'creativity' generated by machinery.
All definitions of Artificial Intelligence seem to use a common thread to sew the principal
objectives and concepts together: artificial intelligence is making human-like decisions with
(non-human) machines. The first (largely theoretical) attempts to quantify 'human'-like thought
largely focused on examination and measuring the ontological notion of intelligence itself. The goal
was to atomize the thought process itself, and replicate it on a machine.
The current approach to artificial intelligence focuses on another very important aspect of the
human experience: data. Often without realizing it, people spend a great
deal of their lives gathering data. We memorize sound combinations in the form of speech, memorize
alphabets, and then vocabularies. We use these words to record and share our data (experiences) with others.
We memorize numbers, symbols, and "facts"; and we observe how others combine those same words, numbers, and symbols
to define solutions to additional problems. Of course, the examples of 'data' are numerous, and frankly, so
vast we often forget the benefits of going through experiences, and storing them in our memory. It's
only recently that computer hardware has allowed machines to gather, store, and then 'recall' data in
organized, and useful ways. And computers have a significant advantage over humans in that they can handle
incredible amounts of data, and they do not ever forget the details within it. The results have indeed been
impressive, but data alone, is not all that begets intelligence.
Two Approaches to Artificial Intelligence: Data-Based versus Objective-Based
There is a critical aspect of 'intelligence' that is being ignored in the recent fervor. Memorizing
inputs, and reproducing them, or recombining them, is not necessarily intelligence. 'Intelligence'
implies critical application of this data for a purpose. If the data-gathering-data-replication
process does not apply critical assessment of the problem itself, it ends up being glorified
'copy-catting'. I had a friend that taught his dog to bark twice when told: "what's one plus one". The
same dog would also bark twice if told: "what's two plus two". Merely taking in letters, words, and
symbols and correlating them to a most probable assurance of following words and symbols is not
intelligence, and it certainly is not creating a solution where a solution didn't exist before.
Creativity and AI
Certainly the 'mimicry' method of problem solving has its merits. As children, as un-informed
adults, we usually use 'try what worked last time' as our baseline problem solution. It often works.
For non-critical, non-difficult problems, its fruit is often sweet enough that we can simply stop
there. However, engineering is a profession that goes beyond the simple answer. We are creators.
It's the job of the engineer to go further than what was tried before. Our job is not to make the
world the same place, it's to make it better.
Engineering is a craft that necessarily requires doing more than barking twice on command. We must know more
than just what the symbols '1', '+', '=', and '2' are; we must know what these symbols mean.
We don't just scribble the symbols, we apply the concepts, so we can tie those
concepts to other concepts (i.e. '3') and generate original answers to original problems. Using data
for engineering is not going to generate solutions to problems that are unique. Afterall, how can we
make a painting that looks like a Picasso, if Picasso didn't first paint it for the world.
But... engineering can certainly benefit from the tools and processes implemented by the current
state-of-the-art research in AI. Assessing data is indeed a critical part of the process, and it's a powerful
tool to solve complex problems, such as fluid mechanics, thermodynamics, reactor design, meteorology,
and quantum mechanics (see Brunton & Kutz's excellent book Data-Driven Science and Engineering)
We just should continue to use our training and human intelligence to create solutions to uncharted
problems. Data is a good starting point, and it serves as an excellent pointer toward the direction
of a solution. But the tools the Data-Driven AI revolution has ushered in can and should be applied to
traditional, Objectively-Quantified solutions too.
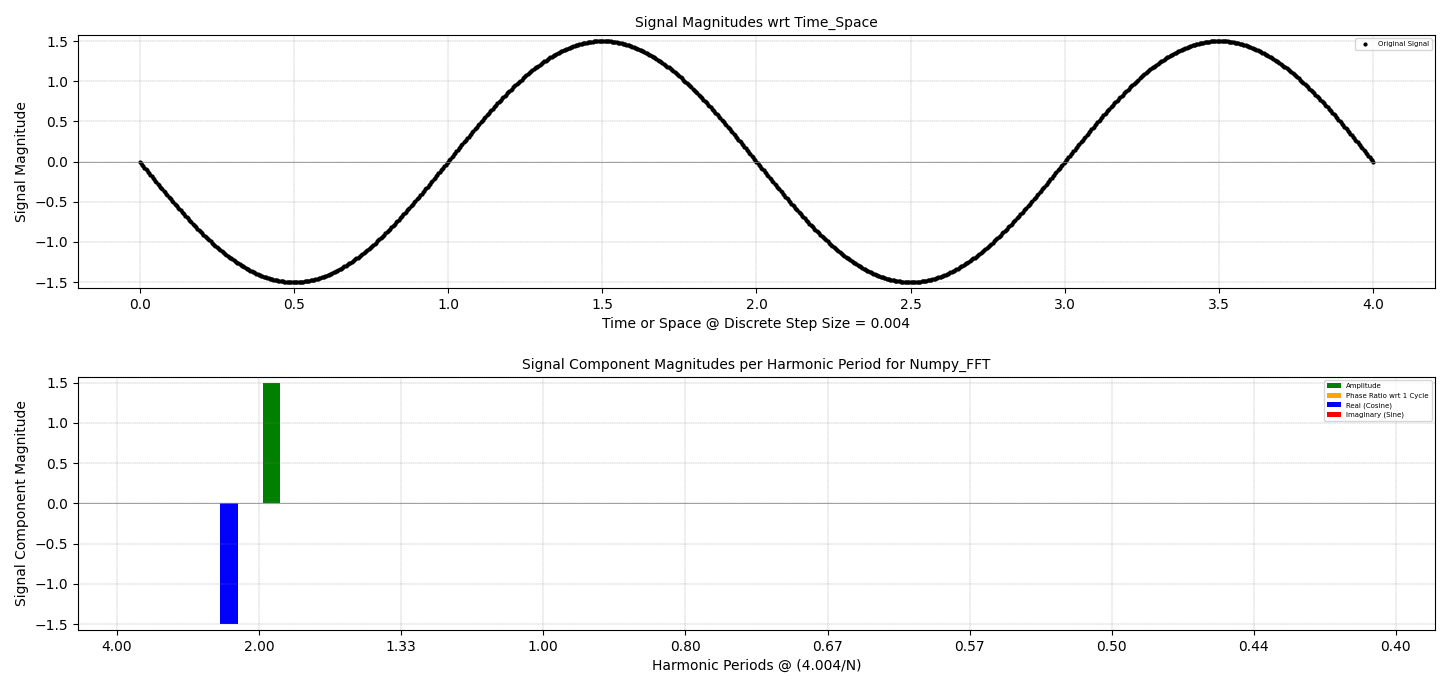
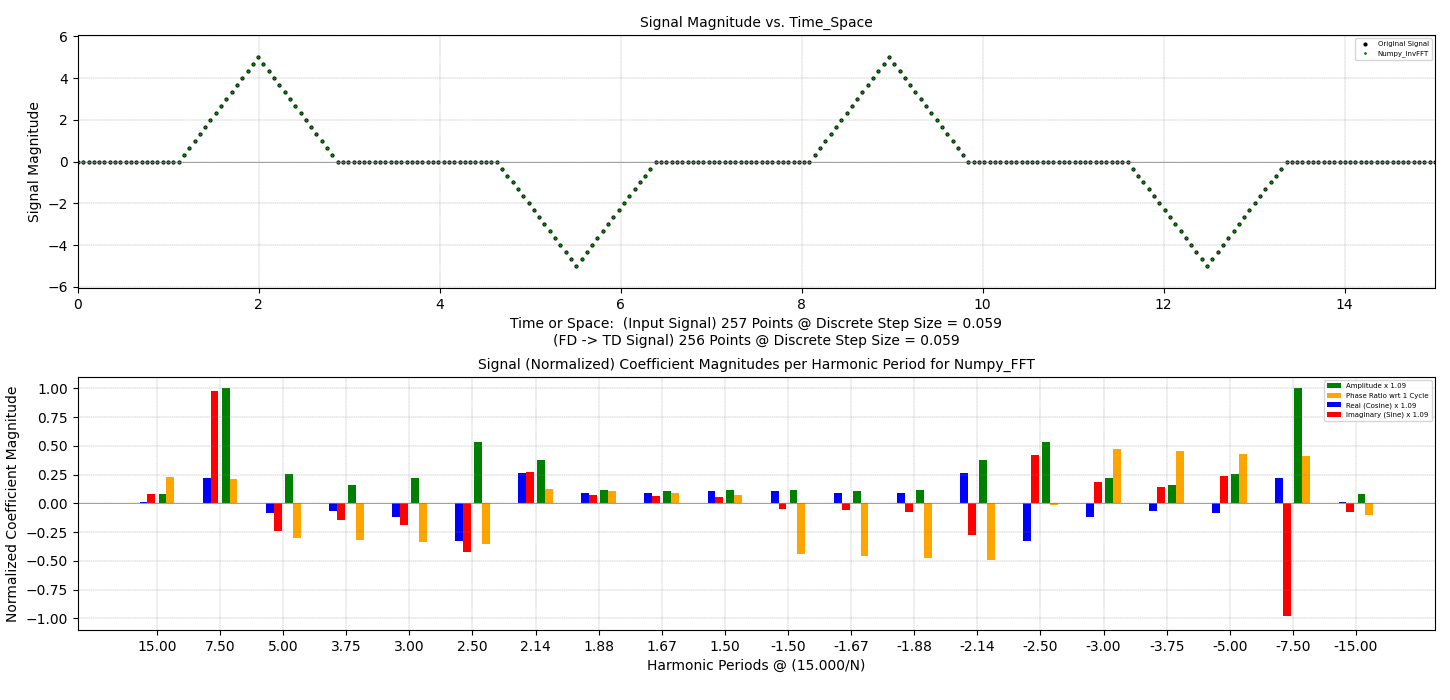
Every physics-based problem has equations used to generate feedback of various physical behaviors that
are relevant to the solution. Those equations are governed by variables that are used to establish the
inputs to that problem definition. In essence, an equation is an engine that takes in information you know
(or are assuming) and processes that information to generate information you do not know. Data-based Artificial
Intelligence uses data directly, in the form of history and examples, to statistically determine the
relationships that exist between the known variables, and the resulting answer. If there are sufficient
examples (a big IF for one-off design) then, a good guess can be gleaned, and then used as a basis for
making future guesses of outcomes. This data-analysis process is popular, and useful, when the data
is sufficient to generate the feedback that is desired. But, more importantly, without sufficient data, generating
predictions of best-design practices is unreliable, or even impossible. And if the data being used to
generate a design could be sub-optimal, or even completely inappropriate.
Fortunately, in our training we learn mathematics and physics. We have the capacity to
generate closed-form solutions, built not of large data sets, but of applied math and applied
physics, with experimentally tested and validated predictions. Our solutions can, and should be,
substituting the data-gathering frenzy with directly-generated solutions. Then, we can use the exact
same numerical tools used by the computer programmers to automate, tune, and improve the quality of
those solutions. We can even use the tools to bypass our biases toward prior (comfortable)
solutions, and then allow us to explore or create new solutions, by examining problems from their
essential components upwards.
In essence, there is computer-intelligence, but since the basis of determining improvement is not refined data, then
we have to conclude there is nothing 'artificial' about the intelligence. It's based on human intervention, and human
intelligence… which has just been augmented using these numerical techniques, also generated by using real intelligence.
Both data-based and physics-based problem solving relies on a similar backend.
Minimizing projections of vector-defined answers that have been factored into principal
components
Allowing pattern matching and reconstruction
Outputs within the vector space are used to generate best-fit recreation of the
output tailored to the user’s request
Mainstream example problems solved by these AI techniques include: search engines,
predictions of user preferences, medical imaging pathology, monitoring real-time and
historical performance for anomalies
Tuning and minimizing the metric norms of state variables to describe and categorize
phenomena used for decision making
Data-based AI might use a neural network(s), and reinforcement learning
Physics-based learning might use Genetic Algorithms and Synthetic Annealing
Mainstream examples using these techniques include: Large Language Models, augmented
reality picture & music, facial recognition/comparisons, resource allocation
optimization
Minimizing variations in solutions to differential equations used to describe random or
quasi-random processes
There is much overlap in using data and physics AI to address problems when it
comes to understanding randomness. Examples include: fluid flow, electrodynamics
fields, or economic systems, & strategic planning
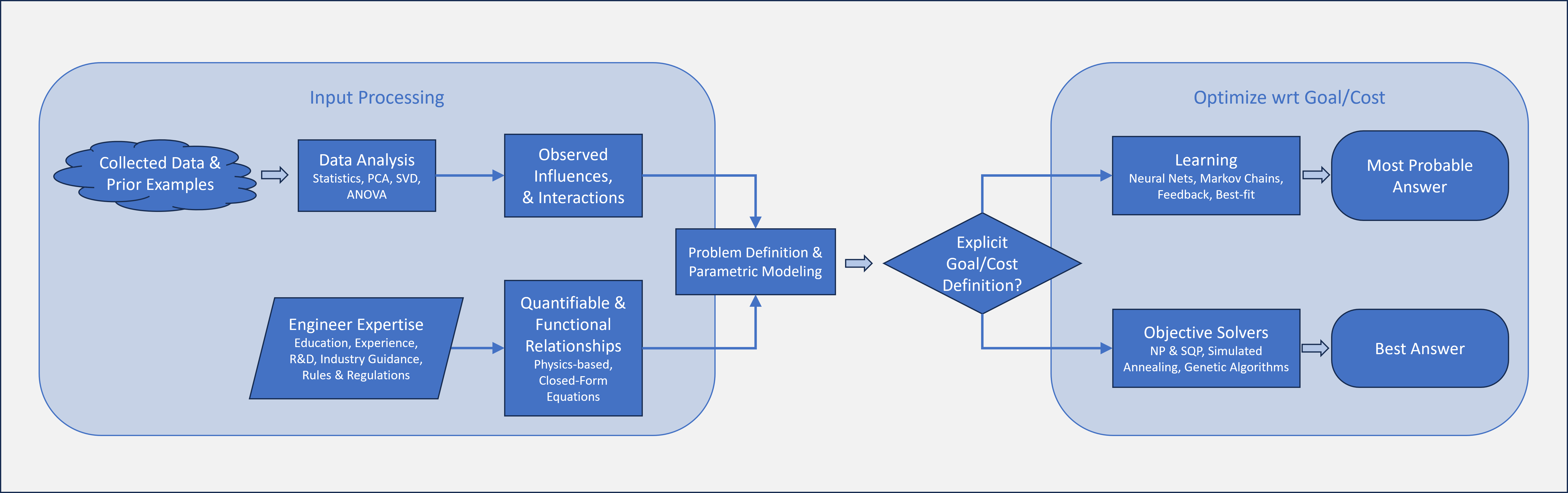
The flow chart below explains the basic approach to design and problem solving. At Windward Mark
Engineering we are applying this process, and using the same numerical tools that have become so
popular with 'mainstream' Artificial Intelligence. But we are pushing the boundaries, as we are not
relying on previous solutions to create new semi-similar solutions to problems. In fact, we argue it
would not be possible. For every dimension of a problem, it would take roughly 20 examples to
statistically arrive at the top 5% answer. And it would take ~20 examples for EACH variable, to
examine the inter-connected effects, and then expect an improvement on the current state-of-the-art.
Windward Mark Engineering is using parametric modeling to automate and generate optimal solutions to
problems -- with no dependency on prior art (as it often doesn't exist).
Logic Flowchart: Physics-Based Problem Solving
The function that is being optimized is called either the Objective Function or the Cost Function.
The idea being, the function (or parametrically-defined process) is being searched wrt the best
"Cost".
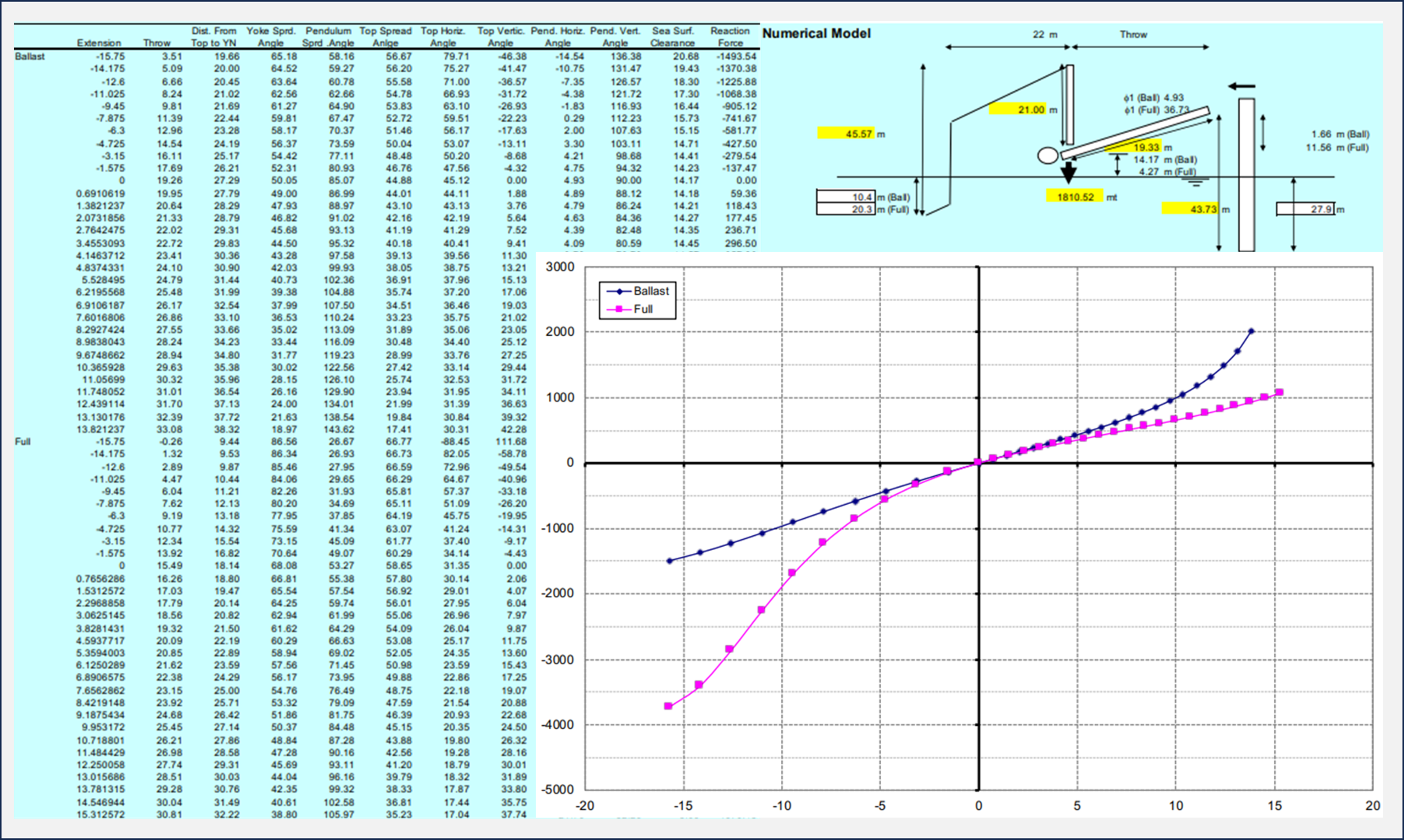
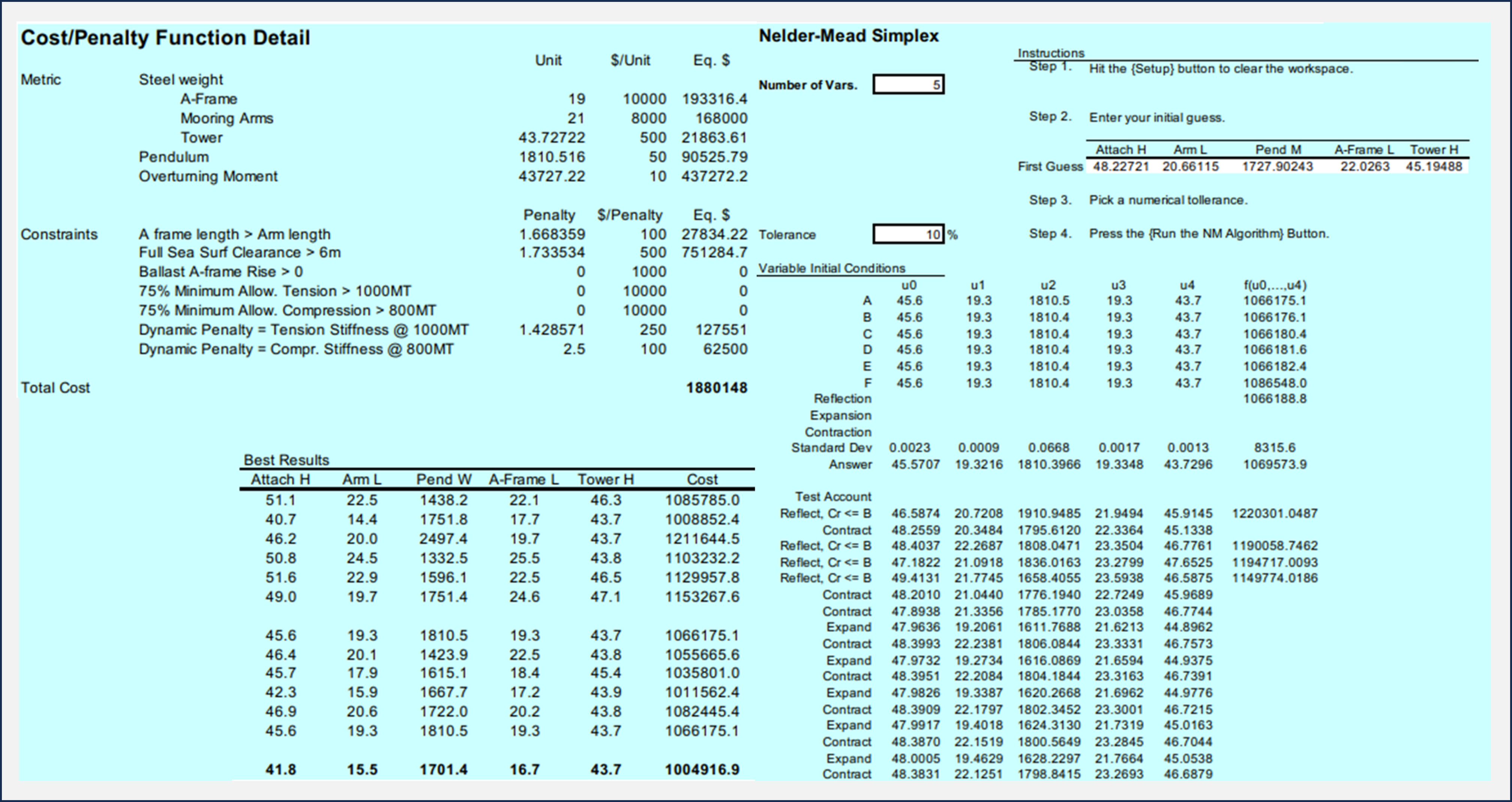
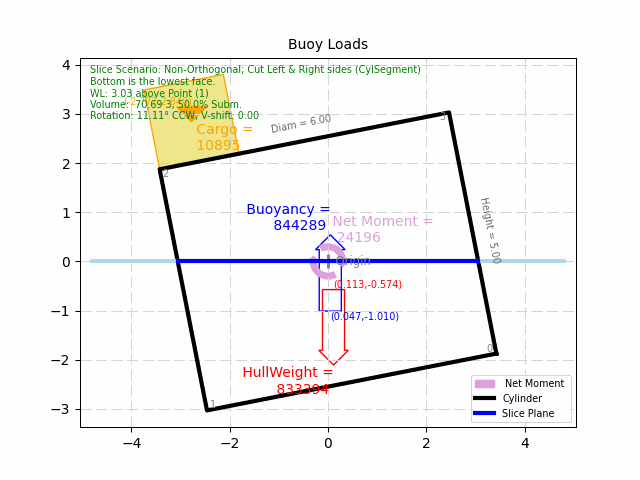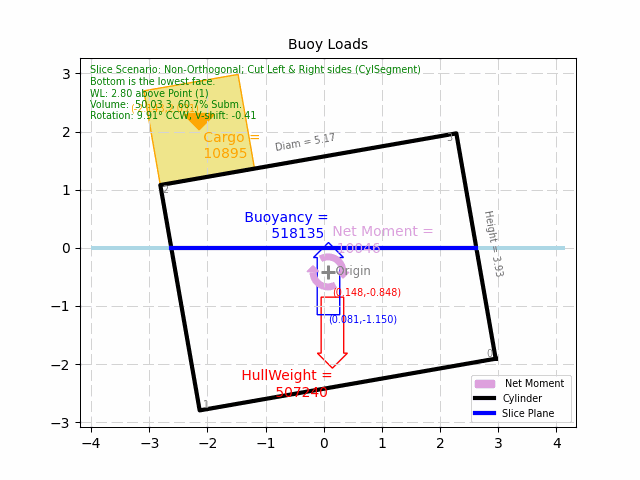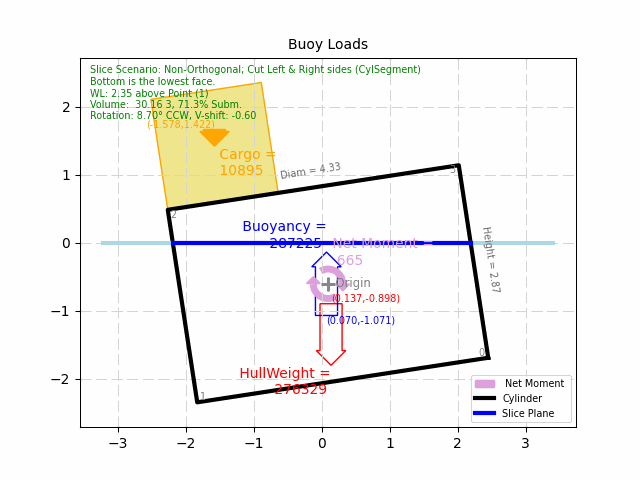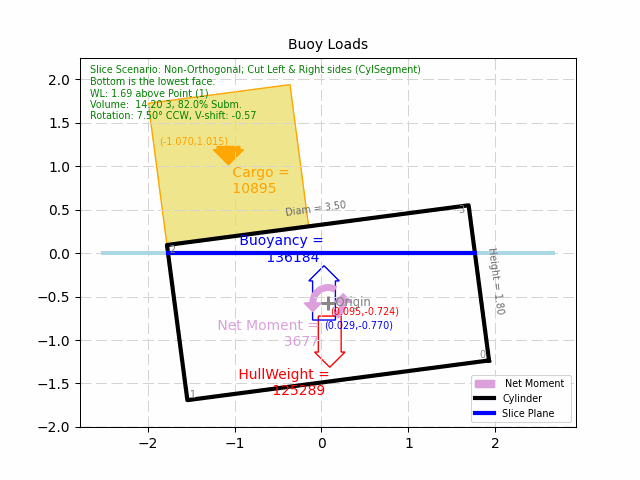
Click here to see an example of this process put into action. The example problem
is a simple, cylinder-shaped buoy, that is optimized for least-mass for a given cargo. The example is simple enough that
someone with a basic understanding of Archimedes' Principle should appreciate what the goal is. It is an innocent
looking problem, but it actually has many possible infeasible solutions and/or local minimum's to explore. (which at
this time, the algorithm is still being developed to handle...) As such, it is an excellent example of how helpful, and
how complicated Optimization can be.
Simple Cylinder-Shaped Buoy Optimization Example
Numerical Automation and Optimization
The central idea to closed-form problem solving involves the idea of a Cost Function (sometimes
referred to as an Objective Function). The Cost Function is THE measurement of success, and it's
critical to all problem solving: knowing what the desired outcome is.
This can be more complicated than it seems. "Cost" is frequently a combination of desired outcomes,
and is often way more than just 'money'. It can often include all of these factors:
Money (literal "cost"), capital expenditure(s), return on investment
Convert the Objective function from a mapping of data through a Neural Network or Markov Chain, to
actual mathematically defined, closed-form physical processes represented by parametric models. The
goal of data-based AI is to minimize the projection of the output vector onto the ideal outcome
vector; the goal of physics-based AI is to minimize the cost of the measured qualities that define a
"cost".
There are many benefits to using this approach to solve Engineering problems.
Ideally, a best solution to the parametric equations used to define a system design or
function
Learning about the system: a) modeling it in increasing number of details, or b) finding
solutions that are unexpected
Once the model is created (model creation can be very tedious), can give very quick results
to the kernel of the problem, giving confidence that the subsequent detail engineering
efforts are effective and fruitful
Can either save money by allowing the user to pocket the savings over 'inferior' solutions;
or can avoid the expense of incorporating unforeseen design flaws into the design
Convex (Differentiable) Optimization Overview
The theory used is called Convex Optimization. It's an idea first proposed by Isaac
Newton in the early
1700's. The basic idea is three steps:
Approximate a Function using the Taylor series.
Differentiate the function and the Taylor Series of that function.
Where the derivative of the Function = 0, there is a min (or max); so, rearrange the
results...
Min where F'(X) = 0, therefore: 0 ≡ F'(X) + F''(X) {... truncate
O3+}
Min @ R ≈ F(X) +
Since Taylor is truncated after Order 2, the residual is approximation of the
remaining difference wrt the min/max
Iterate by plugging in the residual into the original 0 ≡
When the residual is sufficiently small, the approximation is at a local
min/max
The vector of X at this min/max is referred to as the ArgMin
Important: the 0-slope location indicates either a minimum, maximum, OR a
saddle point
NOTE: This article will use the generic term "minimum" to indicate that set of possible
solutions; although it is completely valid to search for a maximum. However, it is highly unlikely to
search for a saddle-point, and care should be taken when assessing a result to check for (unwanted)
saddle point solutions.
The process relies on three very important assumptions:
The function domain and range are continuous
The function domain and range are second-order differentiable (aka it satisfies the
Lipschitz Continuity
condition)
The function domain and range are (locally) convex, which is to say if you pick a point in
the domain, then there is a direction of descent that if followed, will lead to a
minimum/maximum (zero slope)
Constrained Optimization
LaGrange then added to the notion of Convex Optimization, by noticing that:
If there is another function of X, and its domain hyperplane intersects the domain of the
First function,
Then, both functions will have gradients that slope toward a common min/max; but the
magnitudes do not need to be equal. (This ratio of magnitudes is called the
LaGrange Multiplier)
Where those functions have gradients in the same slope, there will be a shared min/max;
which is referred to as an Equality Constraint.
That shared min/max will be a point where the min/max of the First Function (the Objective
Function) will also be a solution of the intersecting function (the Constraint Function)
Furthermore, a solution that satisfies the domain of the intersection, but is not necessarily Equal
to the intersection will be considered feasible (i.e. it can be in the domain less than, or greater
than, if so desired); which is referred to as an Inequality Constraint. So, an Objective Function
can be minimized even if it is not equal to the minimum of the Constraint function (if so
desired).
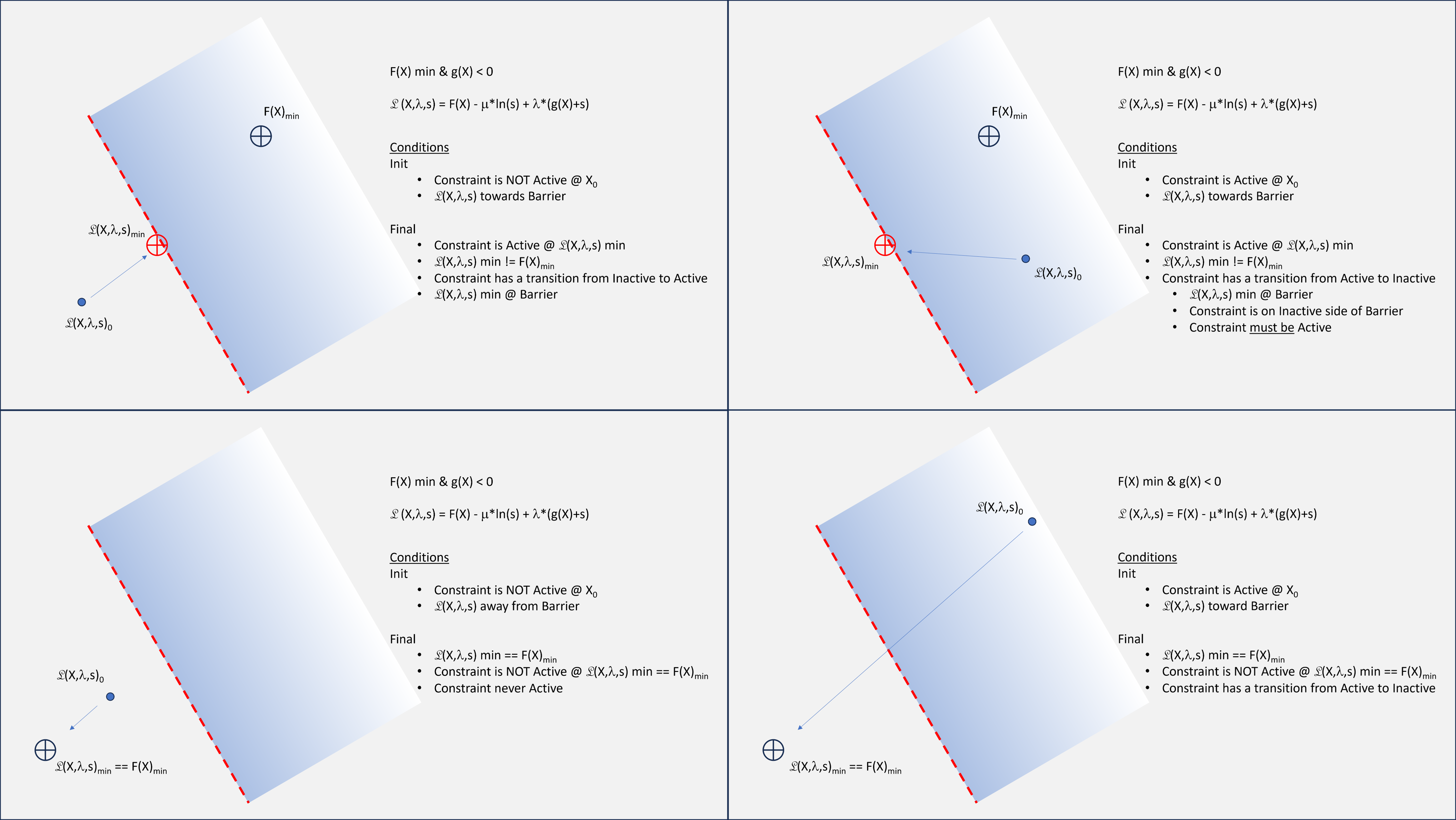
Since many of the techniques used to find the Inequality ArgMins actually generate the location of
an Equality constraint, there are two primary methods of searching for solutions to Inequality
ArgMins.
During each iteration (or perhaps a finite group of iterations) each constraint is checked
for "activeness". If the (current iteration) solution is not at the domain boundary of the
Constraint, then it can be discarded from subsequent iterations altogether. (If it's
'active', continue including the Constraint in the subsequent iterations). This approach is
known as the Active Set approach.
Alternatively, each constraint can be assigned an additional variable that serves as an
artificial offset between the Actual solution to the intersection solution, and the
Artificial solution to the intersection problem. This artificial offset variable is known
as a Slack variable. This artificial offset is increased or decreased as needed, but will
always be used. If the offset is greater than 0, then the Constraint is inactive; but a
closed form solution can be found for each iteration. This approach is known as the Interior
Point approach.
The term "Interior" is in due to convention that artificial offset is always assumed
to be interior, wrt the feasible solution hyperspace.
In actual practice, the slack variable is also forced to be positive by means of
an inverse-exponential multiplier that allows "closeness" to the boundary (but not at
the boundary itself) by increasing/decreasing the Slack variable's influence as needed.
The Taylor series approach to iteratively solving for (and therefore reducing) the remaining
residual lends itself to functions of multiple arguments (not just a single argument). If all the
cross-terms of the interactions between the variables are considered, then the derivatives are said
to be in Quadratic Form. These second derivatives can be organized into matrix form, and this matrix
of second partial derivatives is known as the Hessian matrix, and the collection (Vector) of the first
partial derivatives is known as the Jacobian.
Conveniently, it can be shown that the Constraints can be 'linearized', and these Linearized
coefficients can be collected and merged with the Jacobian. Then, the LaGrange multiplier problem
also can be handled by linearizing the derivatives of the Constraints. These linearized constraint
derivatives are then divided by the subsequent linearized derivative of the Objective Function.
These ratios are then minimized to achieve the most 'collinear' solution of these derivatives
(fulfilling LaGrange's observations that the dual minimum occurs where the Gradients are aligned).
This LaGrange condition can be added as a separate row/column to the solution condition, and becomes
the generalized optimization problem solution.
The Function is now takes on the LaGrange multipliers at part of the Objective to minimize. The
resulting matrix of the quadratic-form Objective Function and the Linearized Equality Constraint(s)
combine with the original Newton approximation (Jacobian * inv(Hessian)) ≈ 0. This
desired solution is referred to as the
Karush-Kuhn-Tucker conditions
, and is solved with the widely available matrix solvers first discovered by Gauss (and is the
subject of much current research in its own right).
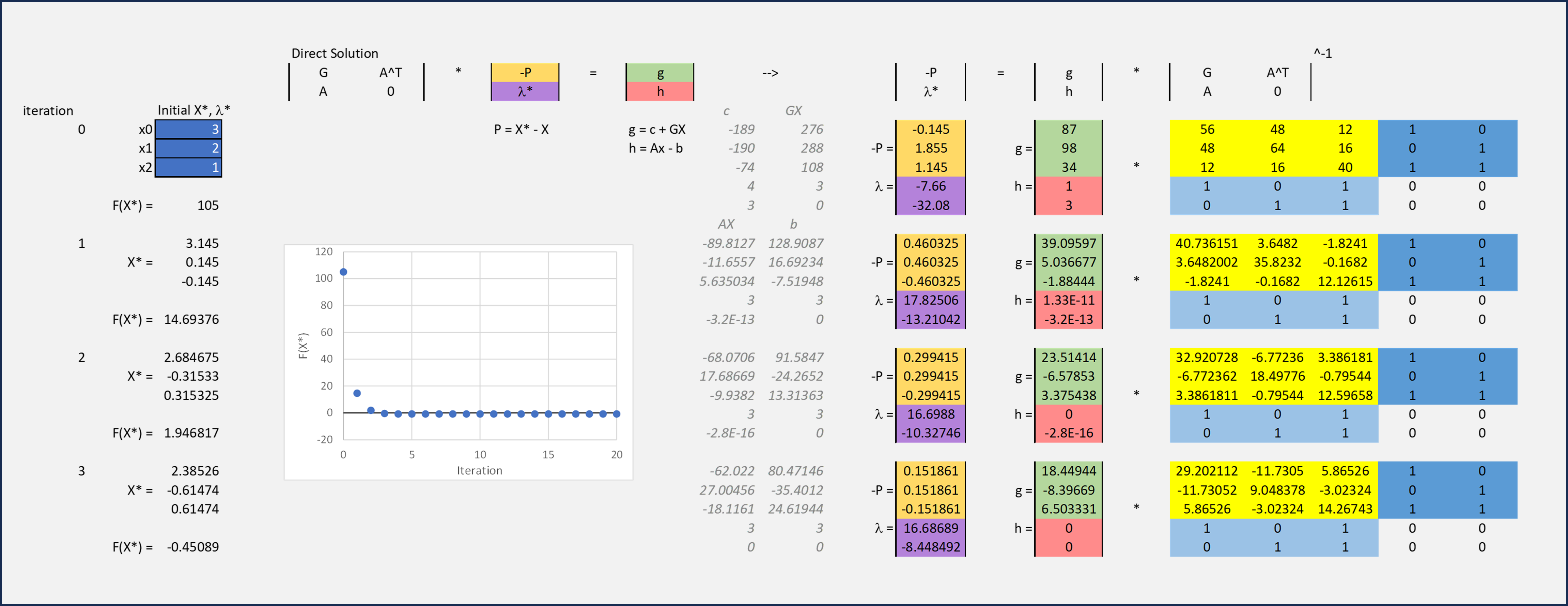
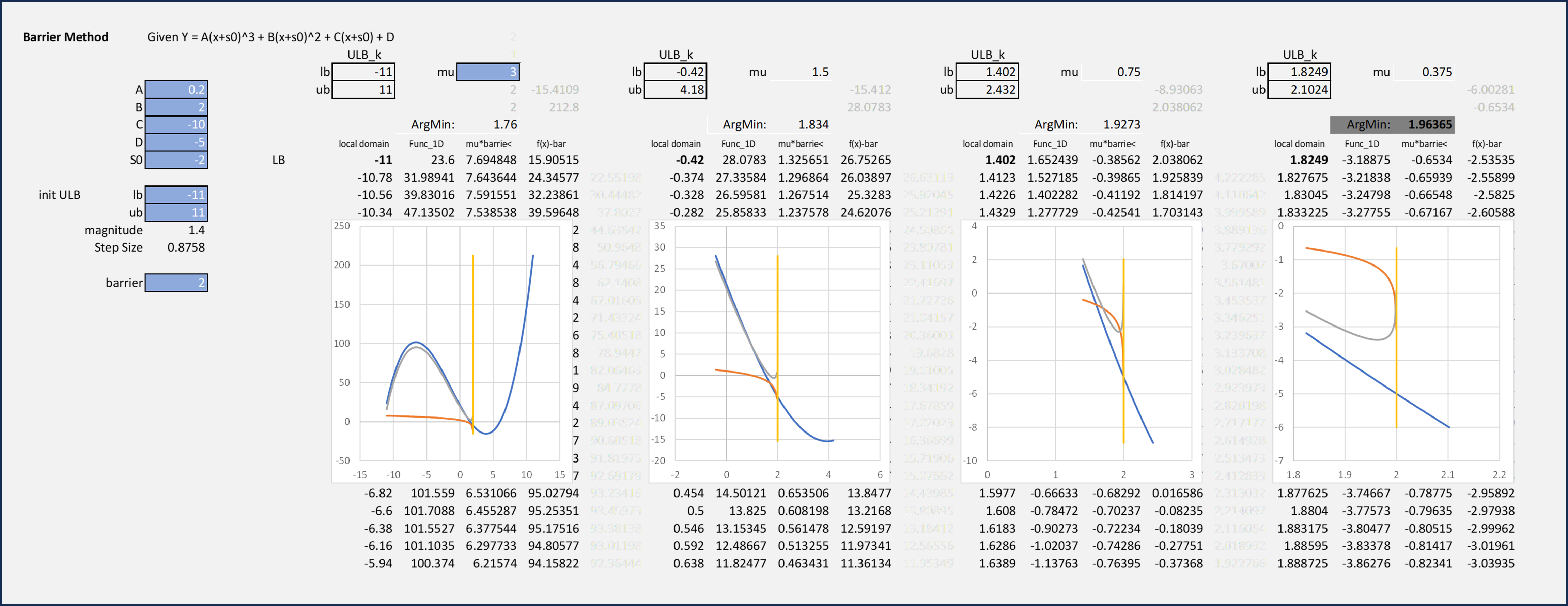
Calculation Example: Direct Matrix Solution via Sequential Quadradic Program
Similarly, the Slack variables can be added to the KKT condition. In the case of the slack
variables, the Slack variable multiplied by the inverse-exponential coefficient (aka barrier
coefficient) is minimized, therefor lending itself to a solver ⇒ 0 approach. The only drawback
is that this is yet another row/column in the matrix solution. The Interior Point approach requires
two extra variables for solving, while the Active Set method, only requires 1, and perhaps fewer if
the Constraints are not active. The tradeoff is a smaller (potentially much smaller) matrix to solve
using AS methods, but the systematic comparisons required for checking 'activeness' both slow
execution and complicate the logic required.
Fortunately the process of generating a quadratic form of the Objective Function lends itself quite
readily to numerical methods. They can be time-consuming (particularly for problems with many
dimensions) as the Hessian is Order N3, but there are approximations to the inverse Hessian, based
on Secant methods, that can bypass the need for the computationally expensive (and sometimes
mathematically impossible) process of generating Hessian matrixes. The result is effective and quick
numerically-based solutions of the optimization process than can be easily handled by today's modern
computer processors.
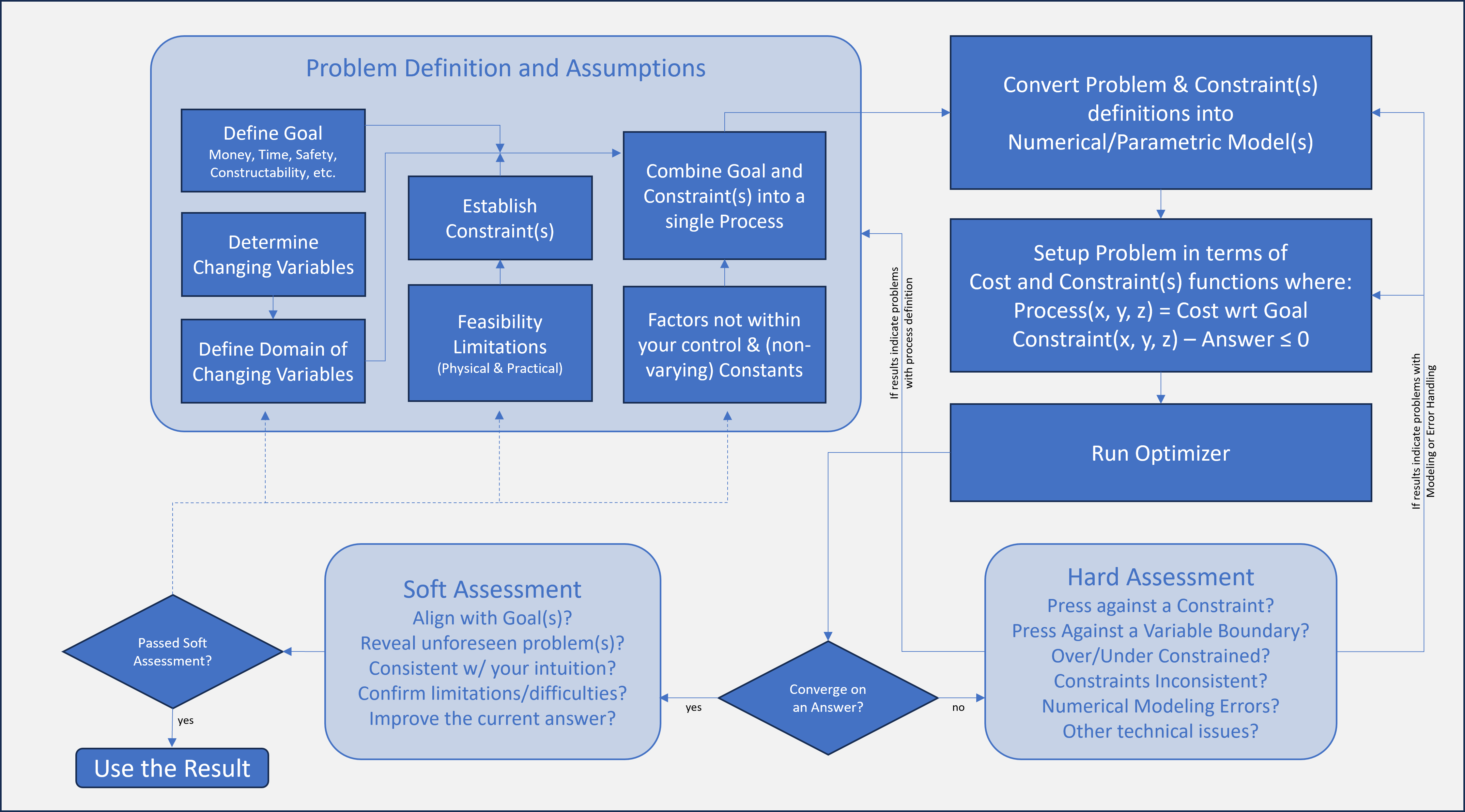
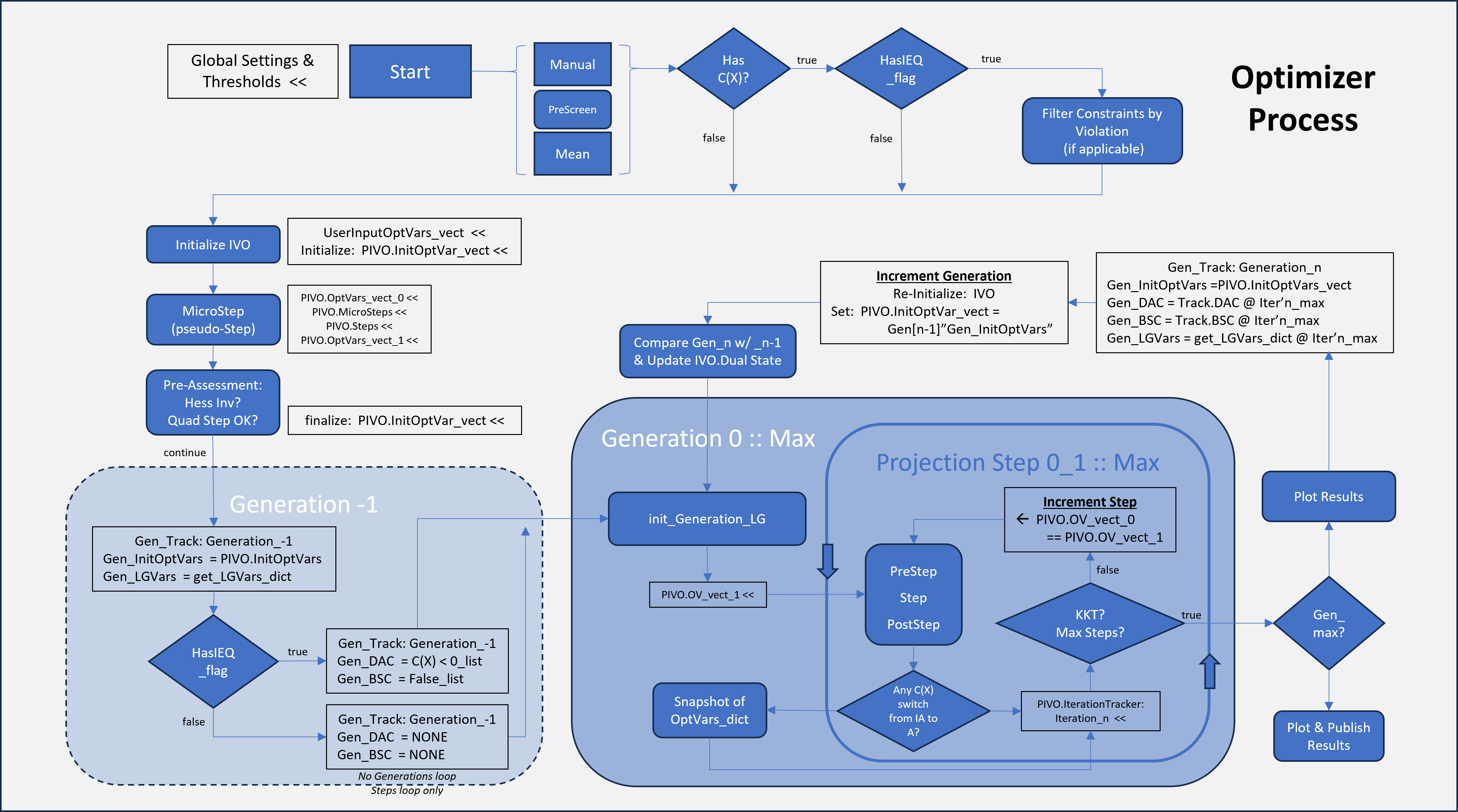
Our Algorithm Approach
Hybrid Interior Point and Active Set
Engineering problems tend to have few-ish variables (compared to data-based optimization using
huge databases of examples), so we have used a hybrid approach
of using Interior Points, but deleting unused constraints as they are deemed un-needed. The Interior
Point method benefits from a re-evaluation process at the end of a limited run of iterations. Our
algorithm does not (necessarily) seek KKT ⇒ 0 as a first priority. We limit the iterations to a
nominal set (usually ~20) iterations, and evaluate trends in 'Generation' runs. At the end of a
Generation, the trackers note if any barriers were ever crossed, or were never crossed. The state of
considered barriers is (re)set, but left unchanged for the duration of the subsequent next
Generation. At each Generation, the slack variable barrier coefficient (inverse-exponential
multiplier) is reduced to allow closer proximity to active barriers (if no state changes were
detected). The next Generation is re-started at the location midway between the Start position and
End position of the previous Generation. Ideally, the barrier state vector does not change from
Generation to Generation and the slack variable barrier coefficients allow closer proximity to the
active constraints.
Logic Scenarios: Hybrid Interior Point and Active Set (click
here for more detials)
Logic Flowchart: Hybrid Interior Point and Active Set by Generation
Calculation Example: Barrier Coefficient by Generation
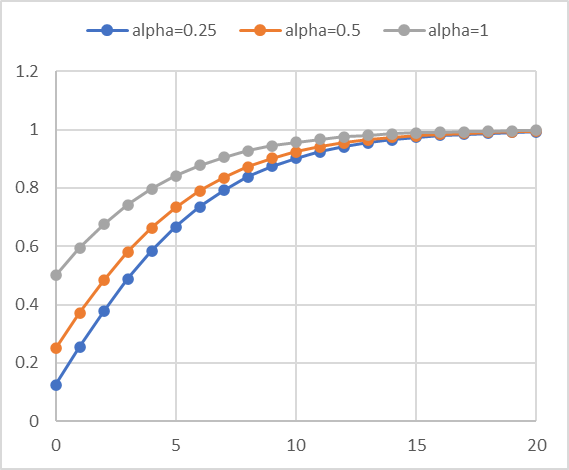
Iteration Alpha vs. Backtracking
The assumption is made that initial solution vectors can (and often do) generate over-predictions of
the gradients. If the Objective Function is Convex, and higher order than quadratic, then this
over-prediction can be significant. For problems with scaling extremes (i.e. an Objective Function
that is comprised of multiple linear dimensions, yielding a (cubic) volume) then the LaGrange
gradient can be quite extreme away from the solution's ArgMin. Therefore, a log-linear reduction is
used for early step advancement. The initial Alpha is half the nominal alpha, while the final Alphas
asymptotically approach 1.
α = TANH( e *
+ ATANH(α/2) )
Calculation Example: Alpha Reduction Factor by Iteration
This approach is considered rather than a more customary backtracking line search approach. Since
the algorithm uses multiple Generations, and cannot achieve KKT convergence in early Generations,
the assumption is made that the adaptions made to the subsequent generations capture improvements
that tend toward better solutions of the ArgMin rather than directly backtracking within a
Generation. In effect, a problem is back-tracked (if needed) from one Generation to the next, instead
of backtracked within a Generation.
Non-Differentiable Options
Annealing and Pseudo-Genetic Algorithms
Not all problems lend themselves to Convex Optimization. The assumptions
of convex optimization cover a large number of problems, and is a very useful tool in most cases. However,
some problems may not be differentiable (or meet the Lipschitz condition); or they may be very complex
with a range of solutions that has many local minima. Selecting an initial condition in such problems will
either generate a false-positive answer, or encounter a discontinuity along the search path and not converge at
all. For such cases, it is necessary to use so-called non-differentiable options. These options can be
used instead of differentiable options, or they can be used as a pre-screener of a problem to perform
brute-force checks of the wider range or answers, to then narrow a convex search to a region which (hopefully)
has a single local minimum.
Non-Differentiable Option: Annealing the Domain (click
here for more details)
Our Algorithm Approach
While developing a model, and before we use Convex Optimization, we often test the model with a broad-band
search and test algorithm. The basic idea is to cast a net, in the form of an M-dimension matrix, that has
been subdivided into N segments. The process is not quick, and for problems with many independent variable
dimensions, the search can be quite large (the search is order M^N). However, the process serves as a good
early examination of the Range behaviors wrt the Input possibilities.
The approach can also be repeated, and serve as a legitimate Automated Optimization option. The process
starts with a wide field of possible options, but after each search, strategic reductions of the dimensions
can be implemented to reduce subsequent generations of searches. The following generations (ideally) permit,
reshaping, and reducing the search domain, and converge on a narrow possible domain for the Cost Function space.
See here for more details on using Pseudo-Genetic Algorithms
This approach has also been used with randomly generated searches, and has allowed consideration of solutions
that circumvent traditional solutions. The results can be unique, and unexpected. When it does find these jewels, the process
definitely enhances the creation of design ideas.
Non-Differentiable Design Example: Wave Energy Conversion Hull (click
here for more details)
Comparison of Non closed-form vs. Quantifiable
Section Text
Advantages and Disadvantages
Section Text
frequently used in Generative Artificial Intelligence